Structuring Data
Designing with Web
This is all about data
Data structures
We left the previous section with the following content on our index.html file, and all our paragraphs messed up by the browser, sticking it all together:
Unlike us, the browser does not understand raw text. In order to render the content of our web pages as we want, we need to structure it using a particuliar syntax: HyperText Markup Language (HTML). And as you'll see with the different languages we'll explore, it's all about formatting data using specific syntaxes.
So before talking about HTML, we need to talk about data and structures. You've probably seen something like that before:

If you've never worked with spreadsheets, have a look at Google Sheets, Microsoft Excel, or OpenOffice Calc, it may be useful.
This is a spreadsheet, a table of cells arranged into rows and columns, used to structure data (here a list of authors). From this, we can tell for each author what are their name, birth date, and date of death.
The visual dimension of tables make it easy to read for humans, but computers can not see (actually Artificial Intelligence makes huge advances on this, but this is not the point). But they can read files. To structure these data using plain text, we can use different syntaxes; for example Comma-Separated Values (CSV) where we take each rows of our table and separate cells values using a , (comma):
name,birth date,date of death
H. P. Lovecraft,20/08/1890,15/03/1937
J. R. R. Tolkien,01/03/1892,09/02/1973
Philip K. Dick,12/16/1928,03/02/1982
CSV is fine for our data, but can become quite messy if we add longer informations like a bio, plus we'll need to escape , characters from our bios to keep the data structure. Another way to structure our data with plain text is using a descriptive Markup Language, like Extensible Markup Language (XML) where all our cells need to be made into XML elements.
Anatomy of an XML element

The main parts of our element are:
- The opening tag: this consists of the name of the element, wrapped in opening and closing angle brackets. This states where the element begins.
- The closing tag: this is the same as the opening tag, except that it includes a forward slash before the element name. This states where the element ends.
- The content: this is the content of the element, which in this case is just text.
- The element: the opening tag, the closing tag, and the content together comprise the element.
Thus, the data of our first author can be written like this:
<name>H. P. Lovecraft</name>
<birth-date>20/08/1890</birth-date>
<date-of-death>15/03/1937</date-of-death>Element names have to be descriptive of what their content represents, and can not contain spaces, therefore we use
-(hyphens) forbirth-dateanddate-of-death.
Nesting elements
We can put elements inside other elements too (this is called nesting), we can then represent the data of our first author this way:
<author>
<name>H. P. Lovecraft</name>
<birth-date>20/08/1890</birth-date>
<date-of-death>15/03/1937</date-of-death>
</author>We are using indentation (spaces at the beginning of lines) to quickly see where elements, enclosing other elements, begin and end. When our data is read, all whitespace characters (like space character, tab character, new line character…) are removed, except between two words were only one space remains. For example, all the followings are equivalent:
<name> H. P. Lovecraft </name>
<name>H. P. Lovecraft</name>
<name>
H.
P.
Lovecraft
</name>
<name>H. P. Lovecraft</name>Finally, our list of authors could be formatted this way:
<authors>
<author>
<name>H. P. Lovecraft</name>
<birth-date>20/08/1890</birth-date>
<date-of-death>15/03/1937</date-of-death>
</author>
<author>
<name>J. R. R. Tolkien</name>
<birth-date>01/03/1892</birth-date>
<date-of-death>09/02/1973</date-of-death>
</author>
<author>
<name>Philip K. Dick</name>
<birth-date>12/16/1928</birth-date>
<date-of-death>03/02/1982</date-of-death>
</author>
</authors>
Using nesting, we can clearly see one advantage of structures like XML over CSV: let's say we want to add a list of books for each authors. While this would be troublesome with CSV, XML-like structures let us add a list of book element inside an element books:
<authors>
<author>
<name>H. P. Lovecraft</name>
<birth-date>20/08/1890</birth-date>
<date-of-death>15/03/1937</date-of-death>
<books>
<book>
<title>The Rats in the Walls</title>
<year>1924</year>
</book>
<book>
<title>The Call of Cthulhu</title>
<year>1928</year>
</book>
</books>
</author>
…
</authors>
Just to be clear, … isn't part of the XML syntax, I'm using it as an ellipsis.
We've seen most of what we need with this type of data structure!

Yet, we need to see 3 more bits of XML before moving on: comments, attributes and XML Declaration.
Comments
In addition to indentation and empty lines, we can add comments to our structure to add informations for us and our collaborators, or to skip an element for tests instead of deleting it. We can add information using single line comment:
<!-- authors are ordered by date of birth -->Or comment a whole element with its content this way:
<!--
<author>
…
</author>
-->
Comments start with <!-- and end with -->, everything that is between won't be read.
We can not add a comment block inside a comment block: no comment inception
.

Attributes
Elements can also have attributes, which look like this:
<author id="lovecraft">…</author>
Attributes contain extra information about the element that we don't want to appear in the actual content. Here, id is the attribute name, and lovecraft is the attribute value. The id attribute allows us to give the element an identifier that can be later used to target the element.
An attribute should always be formated with:
- A space between it and the element name (or the previous attribute, if the element already has one or more attributes).
- The attribute name, followed by an
=(equals) sign. - Opening and closing
"(quotation marks) wrapped around the attribute value.
XML declaration
XML documents begin with an XML declaration that describes some information about themselves:
<?xml version="1.0" encoding="UTF-8"?>
<authors>
…
</authors>This tells the program that should read this file, which version of XML and which set of characters is used in this document, using 2 attributes.
When the XML processor reads an XML document, it encodes the document depending on the type of encoding. It means that each letter written will be stored in a byte. For instance the letter "S" will be encoded into the number "83".
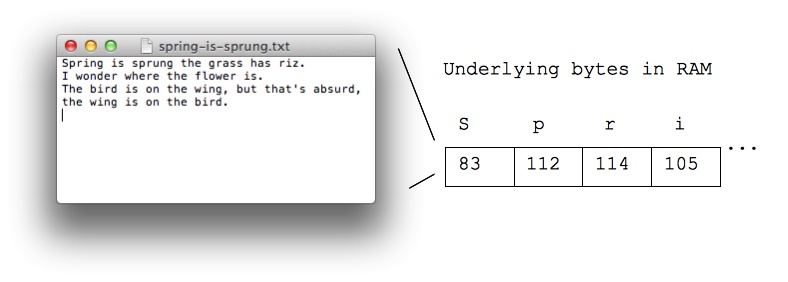
UTF stands for "UCS Transformation Format", and UCS itself means "Universal Character Set". The number "8" or "16" refers to the number of bits used to represent a character. There are mainly two types of encoding:
- UTF-8
- UTF-16
Mix it all!
Finally, here is our structured data using plain text and markup language:
<?xml version="1.0" encoding="UTF-8"?>
<!-- This XML document contains a list of authors -->
<authors>
<author id="lovecraft">
<name>H. P. Lovecraft</name>
<birth-date>20/08/1890</birth-date>
<date-of-death>15/03/1937</date-of-death>
<books>
<book>
<title>The Rats in the Walls</title>
<year>1924</year>
</book>
<book>
<title>The Call of Cthulhu</title>
<year>1928</year>
</book>
</books>
</author>
<author id="tolkien">
<name>J. R. R. Tolkien</name>
<birth-date>01/03/1892</birth-date>
<date-of-death>09/02/1973</date-of-death>
<books>
<book>
<title>The Hobbit</title>
<year>1937</year>
</book>
<book>
<title>The Lord of the Rings</title>
<year>1954</year>
</book>
</books>
</author>
…
</authors>Sum up
- There are different ways to structure data from visual spreadsheets to plain text using CSV or markup languages like XML.
- XML structures data using a special syntax to create elements.
- We choose the name of an element, however this name has to represent the data contained by this element.
- Elements can be nested.
- We can use syntactic sugar like indentation, empty lines and comments to make it easier to read.
- We've discovered syntaxes for attributes inside elements opening tag and XML declaration.
Quiz
Test your knowledge
This quiz is mandatory. You can answer this quiz as many times as you want, only your best score will be taken into account. Simply reload the page to get a new quiz.
The due date has expired. You can no longer answer this quiz.
Good, now that you have some basic data literacy, you're ready to structure a web page using HTML!
